
Overview
- We come across various third-party services that we sometimes need to make a product.
- In this article, we will go through how serverless architecture became an efficient solution for us while integrating third-party services.
- We've used AWS serverless architecture to integrate third-party services with our application.
- We will also discuss the details of how we've broken down various operations of the third-party service and made it work serverless.
About third-party Integration: Logiwa Warehouse Management System
- In one of our recent e-commerce project, we were integrating Logiwa Warehouse Management System API. In this third party integration, there were a few parts that were required to be taken care, for example, managing the inventory, orders and syncing the details back to our application.
- Below are the operations that our integration implemented:
- Inventory Addition / Updation
- helps to manage the inventory.
- Sales / Refund Order
- helps to manage the order transactions.
- Syncing the inventory and sales details back to our system
- helps to keep our system up to date.
- Inventory Addition / Updation
Challenge we could have faced while integrating third-party API
In the traditional approach, we usually place the third party API integration logic in the main application codebase. So if we follow the traditional approach for our Logiwa API integration, then we would have faced below challenges,
- During the sale day, there will be a sudden network traffic burst on customer purchase flow which will increase overall application latency and can eventually bring the system down 😓
- Another challenge would be that if there's an update in third-party API version, then it would require entire codebase to redeploy.
To avoid such issues, we preferred to go with a serverless architecture.
Handle third-party integration efficiently with serverless architecture
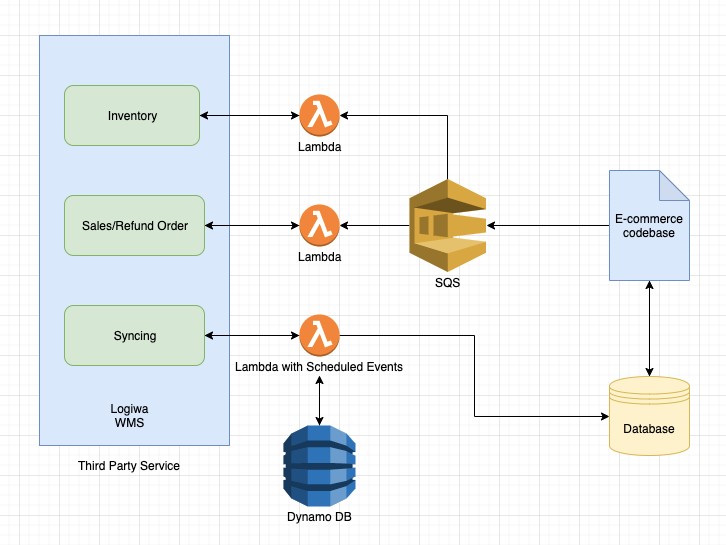
Breaking operation wise serverless module,
-
Inventory Addition / Updation
- To handle inventory, we've created an AWS Lambda to consume inventory addition and updation API.
- We also added queuing service AWS SQS to manage our messages from Logiwa API for AWS Lambda.
- So whenever admin changes an inventory, the data is pushed to an AWS SQS, then lambda which configured to listen to SQS will then consumes the Logiwa third-party API.
- Upon a successful response from a third-party API, our database is synced immediately.
-
Sales / Refund Order
- To handle sales or refund of any order, we've created an AWS Lambda to consume sales and refund third-party API.
- So whenever a customer places an order or request for a refund, the data is pushed to an AWS SQS. Our lambda, listening to AWS SQS messages, will consume the Logiwa third-party API.
- Upon a successful response from a third-party API, our database is synced immediately.
-
Syncing the inventory and order details back to our system
- To sync an inventory and order details from third-party service to our database, we've created a cron job on AWS Lambda with Scheduled Events.
- We also had AWS DynamoDB to handle the state of sync.
- At an interval of every 10 minutes, there will be inventory sync and every 15 minutes interval there will be order sync to our database.
Problem that serverless architecture solves here
- The logic for consuming third-party API could be isolated from the main codebase. Hence individual load can be handled operation wise at optimum cost.
- AWS Lambda can instantly scale up to a large number of parallel executions. Hence the overall solution is highly scalable.
- Gives flexibility of deploying the third-party API update independently.
Further fine-tuning of AWS Lambda could be done for high availability and fault tolerance,
- When we have a third-party outage, then AWS Lambda shall save the messages in AWS S3 along with the reason for failure(outage) and schedule a daily cron job to publish a message from AWS S3 to AWS SQS.
- When we get longer response time than the expected threshold, then AWS Lambda shall save the message in AWS S3 along with the reason for failure(threshold exceeded) and schedule a daily cron job to publish a message from AWS S3 to AWS SQS.
- We would require to configure AWS Lambda to limit concurrency request, which will maintain the request load on the third-party server. So in our case, AWS SQS which is the event source will auto-scale whenever there is a traffic burst on our system.
Thank you for reading.